Examples
FourRooms
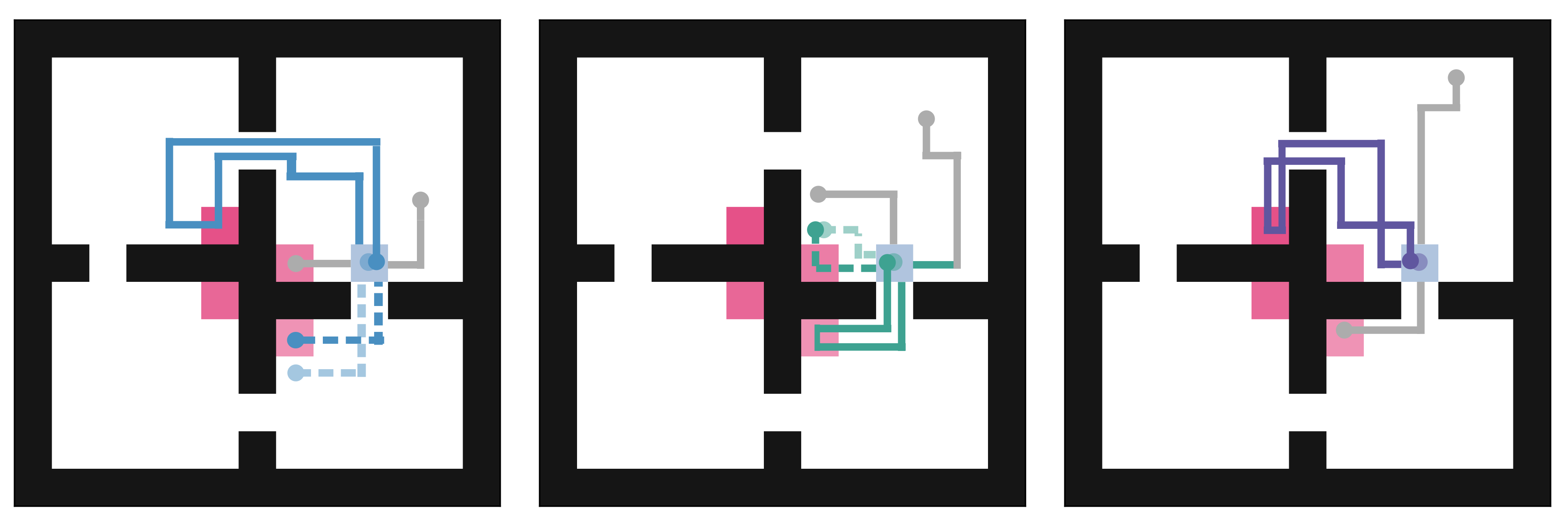
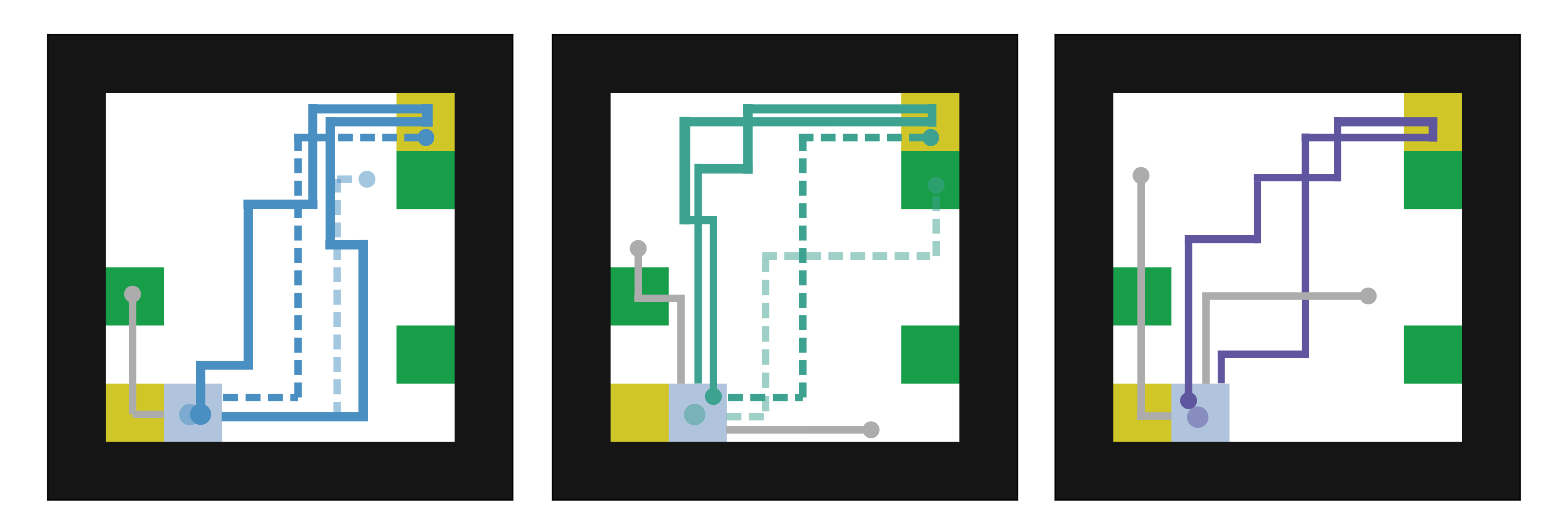
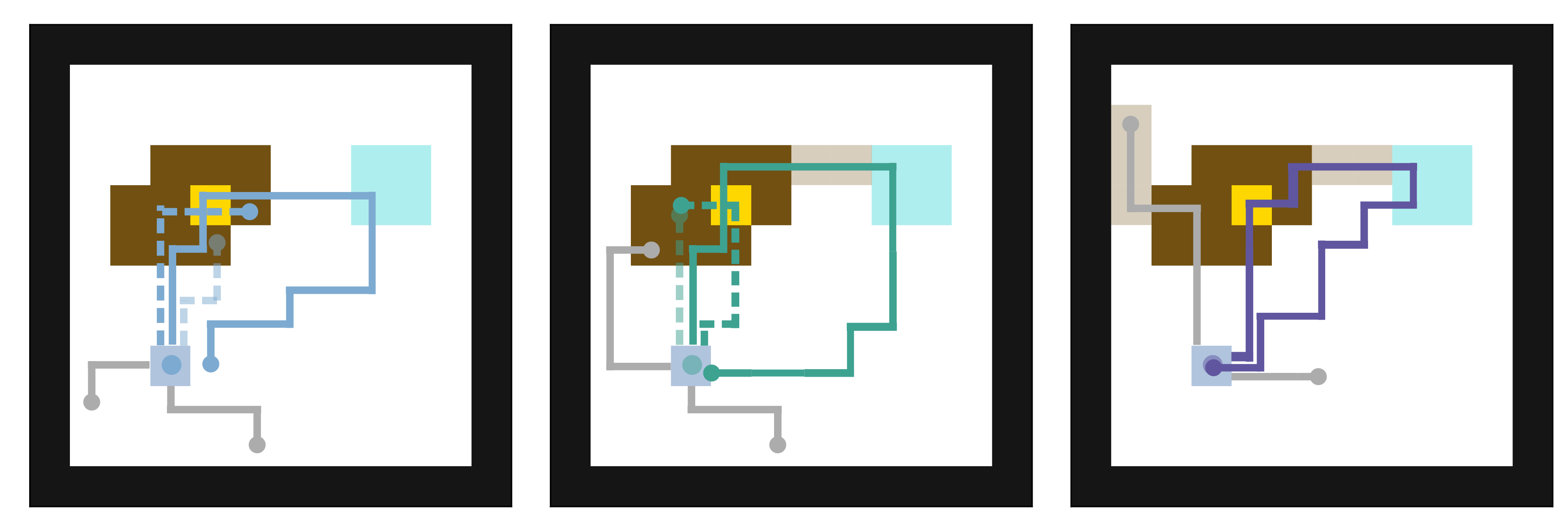
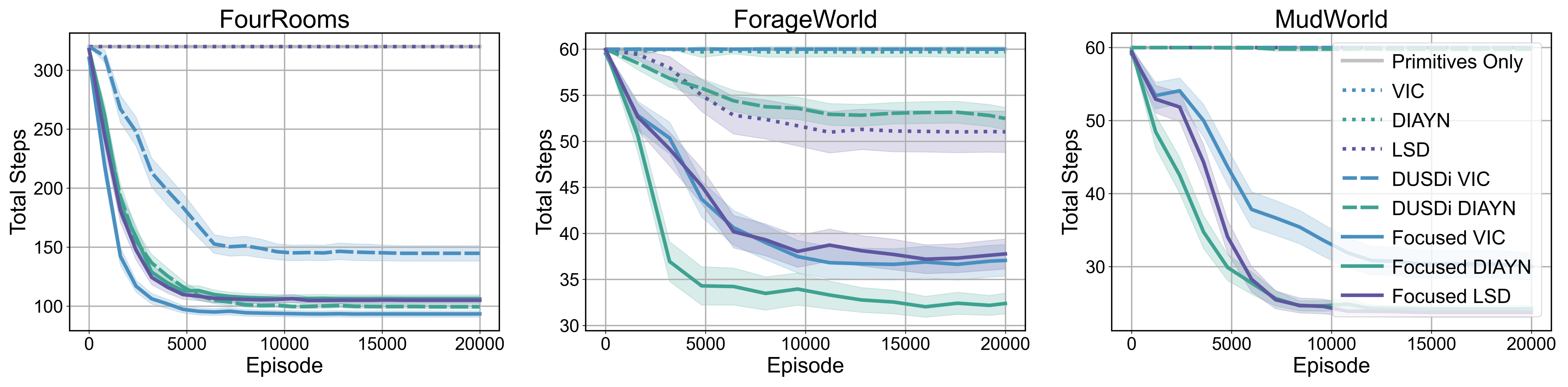
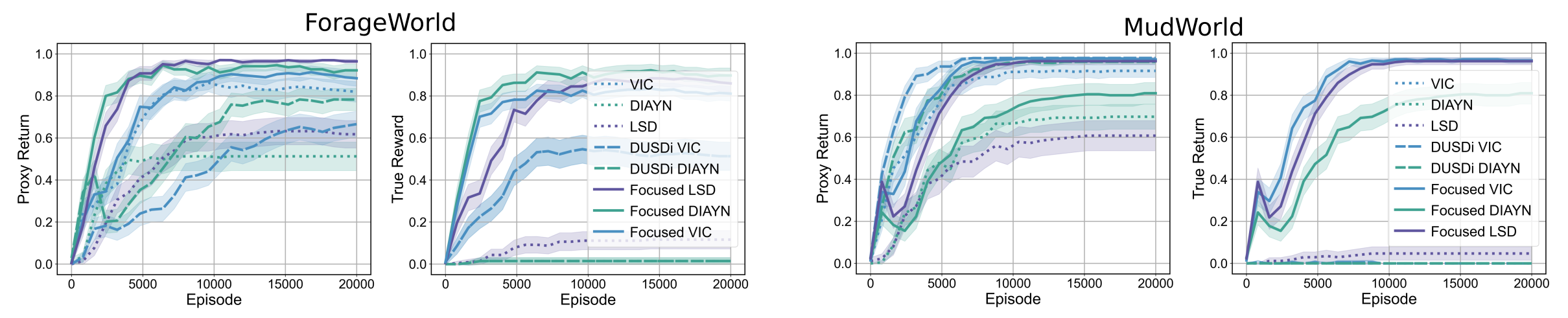
Skills are essential for unlocking higher levels of problem solving. A common approach to discovering these skills is to learn ones that reliably reach different states, thus empowering the agent to control its environment. However, existing skill discovery algorithms often overlook the natural state variables present in many reinforcement learning problems, meaning that the discovered skills lack control of specific state variables. This can significantly hamper exploration efficiency, make skills more challenging to learn with, and lead to negative side effects in downstream tasks when the goal is under-specified. We introduce a general method that enables these skill discovery algorithms to learn focused skills---skills that target and control specific state variables. Our approach improves state space coverage by a factor of three, unlocks new learning capabilities, and automatically avoids negative side effects in downstream tasks.
@article{carr2025focused,
title={Focused skill discovery: {L}earning to control specific state variables while minimizing side effects},
author={Cola{\c{c}}o Carr, Jonathan and Sun, Qinyi and Allen, Cameron},
journal={Reinforcement Learning Journal},
volume={6},
pages={2585--2599},
year={2025}
}